python数据分析 Numpy 概念
Numpy提供了两种基本的对象:ndarray(N-dimensional Array Object)和 ufunc(Universal Function Object)。ndarray 是存储单一数据类型的多维数组,而ufunc 则是能够对数组进行处理的函数。
数据类型
numpy数组计算基础 numpy数组 数组的属性 ndarray(数组)是存储单一数据类型的多维数组。
属性 说明
ndim 返回 int。表示数组的维数
shape 返回 tuple。表示数组的尺寸,对于 n 行 m 列的矩阵,形状为(n,m)
size 返回 int。表示数组的元素总数,等于数组形状的乘积
dtype 返回 data-type。描述数组中元素的类型
itemsize 返回 int。表示数组的每个元素的大小(以字节为单位)。
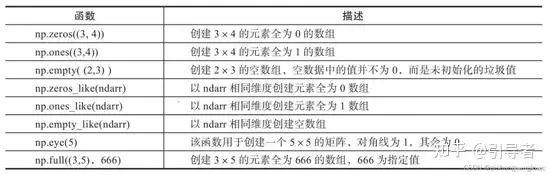
数组的创建 numpy.array() 1 numpy.array(object , dtype = None , copy = True , order = None , subok = False , ndmin = 0 )
object
数组或嵌套的数列
dtype
数组元素的数据类型,可选
copy
对象是否需要复制,可选
order
创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
subok
默认返回一个与基类类型一致的数组
ndmin
指定生成数组的最小维度
1 2 3 4 5 6 7 8 9 10 11 import numpy as np a = np.array([1 ,2 ,3 ]) print (a) a = np.array([[1 , 2 ],[3 , 4 ]]) print (a)
numpy.arange() 1 np.arange( start,stop,step,dtype)
参数
描述
start起始值,默认为0
stop终止值(不包含)
step步长,默认为1
dtype返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。
numpy.linspace numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
1 np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数
描述
start序列的起始值
stop序列的终止值,如果endpoint为true,该值包含于数列中
num要生成的等步长的样本数量,默认为50
endpoint该值为 true 时,数列中包含stop值,反之不包含,默认是True。
retstep如果为 True 时,生成的数组中会显示间距,反之不显示。
dtypendarray 的数据类型
numpy.logspace numpy.logspace 函数用于创建一个于等比数列。格式如下:
1 np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
base 参数意思是取对数的时候 log 的下标。
参数
描述
start序列的起始值为:base ** start
stop序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中
num要生成的等步长的样本数量,默认为50
endpoint该值为 true 时,数列中中包含stop值,反之不包含,默认是True。
base对数 log 的底数。
dtypendarray 的数据类型
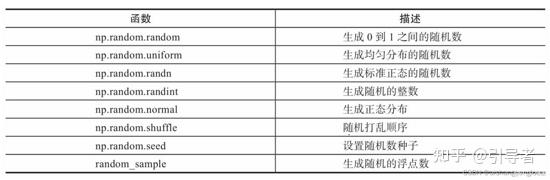
生成随机数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import numpy as nparr1 = np.random.randn(3 , 3 ) arr2 = np.random.rand(3 , 3 ) arr3 = np.random.uniform(0 , 10 , 2 ) arr4 = np.random.randint(0 , 10 , 3 ) print (f'arr1 : {arr1} \narr2 : {arr2} \narr3 : {arr3} \narr4 : {arr4} ' )out :
索引访问数组 一维数组索引 [start:stop:step]
多维数组索引 [行索引 , 列索引]
整数序列索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import numpy as np x = np.array([[1 , 2 ], [3 , 4 ], [5 , 6 ]]) y = x[[0 ,1 ,2 ], [0 ,1 ,0 ]] print (y)out: x = np.array([[ 0 , 1 , 2 ],[ 3 , 4 , 5 ],[ 6 , 7 , 8 ],[ 9 , 10 , 11 ]]) rows = np.array( [ [0 ,0 ],[3 ,3 ] ] ) cols = np.array( [ [0 ,2 ],[0 ,2 ] ] ) y = x[rows,cols]
布尔值索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import numpy as np x = np.array([[ 0 , 1 , 2 ],[ 3 , 4 , 5 ],[ 6 , 7 , 8 ],[ 9 , 10 , 11 ]]) print ('我们的数组是:' )print (x)print ('\n' )print ('大于 5 的元素是:' )print (x[x > 5 ])out:
变换数组形态 np.reshape(arr ,newshape, order=”c”)
展平数组
1 2 3 arr.ravel() arr.flatten('F' )
合并数组
1 2 3 4 5 np.hstack((arr1,arr2)) np.vstack((arr1,arr2)) np.concatenate((arr1,arr2),axis=1 )
分割数组
1 2 3 4 5 np.hsplit(arr,2 ) np.vsplit() np.split(arr,2 ,axis= )
numpy矩阵 创建矩阵
1 2 3 4 5 matr1=np.mat("1 2 3; 4 5 6" ) matr2=np.matrix([[1 ,2 ,3 ],[4 ,5 ,6 ]]) np.bmt('arr1,arr2;arr3,arr4' )
矩阵属性
1 2 3 4 mat.T mat.H mat.I mat.A
ufunc函数 通用函数,对数组中所有元素进行操作的函数。
ufunc的广播机制
不同形状数组之间执行算数运算的方式,ufunc会对形状相同的两个数组的对应元素进行计算,当两个数组形状不同时会实行广播机制
遵循4个原则
1.所有的输入数组向其中的shape最长的数组看齐,shape不足前面加1补齐
2.输出数组的shape是输入数组shape在各个轴上的最大值组合
3.两个数组的行或列要相同且其中一个数组的行或列为1
4.当输入数组的某个轴的长度为1时,使用此轴上的第一组值进行运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 arr1=np.array([[0 ,0 ,0 ],[1 ,1 ,1 ],[2 ,2 ,2 ],[3 ,3 ,3 ]]) arr2=np.array([[1 ,2 ,3 ]]) print (arr1,arr2) print (arr1+arr2)print ("-" *80 )arr3=np.array([[1 ,2 ,3 ,4 ]]).reshape(4 ,1 ) print (arr3)print (arr3+arr1)[[0 0 0 ] [1 1 1 ] [2 2 2 ] [3 3 3 ]] [[1 2 3 ]] [[1 2 3 ] [2 3 4 ] [3 4 5 ] [4 5 6 ]] -------------------------------------------------------------------------------- [[1 ] [2 ] [3 ] [4 ]] [[1 1 1 ] [3 3 3 ] [5 5 5 ] [7 7 7 ]]
numpy统计分析 读写文件 1 2 3 4 5 6 7 8 9 10 11 np.save('保存路径/文件名' ,arr) np.savez('' ,arr1,arr2) data=np.load("文件" ) np.savetxt('路径' ,arr,fmt,delimiter) np.loadtxt() np.genfromtxt()
利用函数进行简单统计分析 排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 arr.sort() arr[::-1 ] arr.argsort() arr.lexsort(keys axis) a = np.random.randint(1 , 100 , size=5 ) b = np.random.randint(1 , 100 , size=5 ) c = np.random.randint(1 , 100 , size=5 ) d = np.lexsort((a, b, c)) print (list (zip (a[d],b[d],c[d]))) print (d)print (c[d])print (a[d])[20 32 75 56 84 ] [60 92 74 97 50 ] [54 74 9 53 31 ] [(75 , 74 , 9 ), (84 , 50 , 31 ), (56 , 97 , 53 ), (20 , 60 , 54 ), (32 , 92 , 74 )] [2 4 3 0 1 ] [ 9 31 53 54 74 ] [75 84 56 20 32 ]
去重和重复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 np.unique(arr) arr2=np.arange(5 ) print (arr2,"\n" ,np.tile(arr2,3 ))[0 1 2 3 4 ] [0 1 2 3 4 0 1 2 3 4 0 1 2 3 4 ] arr3 = np.random.randint(1 , 100 , size=[3 , 3 ]) print (arr3,"\n\n" ,arr3.repeat(2 ,axis=0 ))[[80 15 93 ] [59 75 23 ] [ 4 92 72 ]] [[80 15 93 ] [80 15 93 ] [59 75 23 ] [59 75 23 ] [ 4 92 72 ] [ 4 92 72 ]]
常用统计函数 1 2 3 4 5 6 7 8 np.sum (arr,axis) np.mean() np.std() np.var() np.min () / max () np.argmin() max () np.cumsum() / cumprod() item=data['item_id' ].value_counts()
Pandas统计分析 读写数据 1 2 3 4 pd.read_csv() pd.read_excel() dataframe.to_csv() dataframe.to_excel()
读写数据库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pdfrom sqlalchemy import create_engineengine=create_engine('mysql+pymysql://root:lv513233@127.0.0.1:3306/a?charset=utf8' ) print (engine)listdata=pd.read_sql_query('show tables' ,con=engine) print (listdata)news_data=pd.read_sql_table('news' , con=engine) print (news_data)news_data.to_sql('news_data' ,con=engine,if_exists='replace' )
DataFrame 常用属性 1 2 dataframe.values,index,columns,dtypes dataframe.size,ndim,shape,T
增删改查dataframe
查
1 2 3 4 5 6 7 8 9 10 11 12 13 14 df.loc[:,'A' ] df.iloc[:,1 ] df.loc[:,['A' ,'B' ]] df.loc[2 :6 ,['A' ,'B' ]] df.loc[[1 ,3 ,5 ],['A' ,'B' ]] df.iloc[2 :6 ,[1 ,3 ]] df.loc[df['A' ]=='a' ,['A' ,'B' ]] df.iloc[(df['A' ]=='a' ).value,[1 ,2 ]]
改
1 df.loc[df['A' ]=='a' ,'A' ]=1
增
删
1 2 3 df.drop(labels,axis,inplace) df.drop(labels='A' ,axis=1 ,inplace=True ) df.drop(labels=range (1 :4 ),axis=0 ,inplace=True )
描述性分析DataFrame数据 1 2 3 4 5 6 7 8 df['A' ].mean /describe() df['B' ].value_counts()[:6 ] df['A' ].astype('category' )
转换处理时间序列数据 转化时间字符串为标准时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pd.to_datetime(df['A' ],errors,dayfist/yearfirst) data['timestamp' ] = pd.to_datetime(data['timestamp' ], unit='s' ) data = data.apply(lambda x:time.mktime(x.timetuple())) pd.DatetimeIndex() pd.PeriodIndex()
提取时间序列数据信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 data["year" ]=[i.year for i in data["date" ]] data["month" ]=[i.month for i in data["date" ]] data['date' ] = data['timestamp' ].dt.date data['date' ] = pd.to_datetime(data['date' ]) data['time' ] = data['timestamp' ].dt.time data['hour' ] = data['timestamp' ].dt.hour dateIndex.weekday[:5 ]
加减时间数据
1 2 3 4 5 6 time=data["date" ]+pd.Timedelta["days=1" ] time=data["date" ]-pd.Timedelta['2024-1-1' ]
分组聚合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 musicdataGroup=musicdata[['format' ,'metric' ,'value_actual' ]].groupby(by='format' ) data[['number_records' ,'value_actual' ]].agg([np.sum ,np.mean]
创建透视表和交叉表 pivot_table 创建透视表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 povot_data=pd.privot_table(data[['format' ,'number_records' ,'value_actual' ]], index='format' ,aggfunc=np.sum ) povot_data=pd.privot_table(data[['format' ,'metric' ,'number_records' ,'value_actual' ]], index=['format' ,'metric' ],aggfunc=np.sum ) povot_data=pd.privot_table(data[['format' ,'number_records' ,'value_actual' ]], index='format' ,columns='metric' ,aggfunc=np.sum ) povot_data=pd.privot_table(data[['format' ,'number_records' ,'value_actual' ]], index='format' ,values='value_actual' ,aggfunc=np.sum ) povot_data=pd.privot_table(data[['format' ,'number_records' ,'value_actual' ]], index='format' ,columns='metric' ,aggfunc=np.sum ,fill_value=0 ) povot_data=pd.privot_table(data[['format' ,'number_records' ,'value_actual' ]], index='format' ,columns='metric' ,aggfunc=np.sum ,fill_value=0 ,margins=True )
crosstab创建交叉表 计算分组频率
1 2 crosstab_data=pd.crosstab(index=data['format' ],columns=data['metric' ], values=data['value_actual' ],aggfunc=np.sum )
Pandas数据预处理 堆叠合并数据 1 2 3 4 5 6 7 8 9 10 11 12 d1=pd.concat([df1,df2],axis=1 ,join="outer" ) d2=pd.concat([df1,df2],axis=0 ,join="outer" ) print (d1)print (d2)
主键合并数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 data1=pd.read_csv("user_download.csv" ,encoding='gb18030' ) data2=pd.read_csv("user_pay_info.csv" ) data3=pd.merge(data1,data2,left_on="用户编号" ,right_on="编号" ) print (data3)data2.rename(columns={'编号' :'用户编号' },inplace=True ) download_pay1=data1.join(data2,on='用户编号' ,rsuffix='1' )
清洗数据 去重 记录重复
1 2 3 4 5 6 7 print (data.duplicated().sum ())df['A' ].drop_duplicates() df.drop_duplicates(subset['A' ,'B' ])
特征重复
去除连续的特征重复,利用特征间的相似度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 df[['A' ,'B' ]].corr(method='kendall' ) d_euqlas=user_data["用户编号" ].equals(user_data["编号" ]) def feature_equals (df ): df_equals=pd.DataFrame([]) for i in df.columns: for j in df.columns: df_equals.loc[i,j]=df.loc[:,i].equals(df.loc[:,j]) return df_equals app_desire=feature_equals(user_data) print (app_desire.iloc[:7 ,:7 ])len_feature=app_desire.shape[0 ] dup_col=[] for m in range (len_feature): for n in range (m+1 ,len_feature): if app_desire.iloc[m,n]&(app_desire.columns[n] not in dup_col): dup_col.append(app_desire.columns[n]) print ('需要删除的列' ,dup_col)
检测与处理缺失值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 df.isnull().sum () df.dropna(axis=0 ,how="any" ) mean_mun=df['A' ].mean() df['A' ]=df['A' ].fillna(mean_num) from scipy.interpolate import interpld
异常 Matplotlib可视化 seaborn